
A new villain: the Cybergoat 🐐
The past weeks have highlighted the disparity between the accountability of digital systems and that of their creators. Now is the time to educate each other and demand transparency, before algorithms become the ultimate scapegoat.


Update: 10th January 2021
Since first writing about the "Cybergoat" there's been a significant and positive change to the Deliveroo case, which I mention later in this article.
Last year a consortium of Deliveroo drivers, backed by Italy's largest trade union CGIL, took Deliveroo to court over an algorithm that penalised drivers if they cancelled shifts less than 24 hours in advance. If they did this, it would reflect poorly on the driver's 'reliability' score and they would subsequently be offered fewer shifts.
Deliveroo initially hedged blame, accusing the 'algorithm' of making a mistake rather than their implementation of it causing the penalisation. This refusal to admit responsibility is just another example of the cyber-scapegoat or "cybergoat" being used to perform unfavourable actions through the guise of a "faceless" digital entity. However, this time, in this historic ruling, the Italian courts ruled against Deliveroo, noting that they were responsible for implementing the "discriminatory" algorithm and consequently are at fault. The drivers who sued Deliveroo were awarded €50,000. This ruling is an excellent step towards discouraging corporations from using such methods and consequently discouraging the Cybergoat from rearing its ugly head again.
It seems that we've entered the cyberpunk stage of 2020, a year that will never cease to amaze 🌈. This month protesters in London spent a weekend shouting 'fuck the algorithm' in parliament square after thousands of students found themselves unexpectedly missing out on university places. An 'algorithm' designed by Ofqual (a government regulator) had been used to broadly amend teacher-submitted grades (CAGs) for this year's A-levels, downgrading 40% of marks by up to four levels.
People began to question: why would an algorithm do this? What's the logical reasoning behind amending an A to a D? A human would never do this. Broadcasters focused blame on the algorithm, as though a personified silicon demon had brutally crushed the hopes of thousands of students for the sheer hell of it. Despite this trashfire, Ofqual and the government repeatedly spoke of their 'full confidence' in said 'algorithm' - only to give up days later, when they began condemning the algorithm and instead awarded students their teacher-submitted grades.
This ordeal reminded me of a cryptic note that I found written on my phone's to-do list months ago, right under 'massive cats?' (no idea):
'algorithms are the perfect scapegoat'.
A cybergoat, if you will. Why? Because people distrust technology, arguably even more than they distrust politicians - and why wouldn't they? We are surrounded by technology that breaks all the time. At Fast Familiar, I have the privilege of seeing a vast range of people accessing technology during our shows. At first I ignorantly assumed that their affinity to tech would just correlate with age, which to some extent it does. With older generations, the flaws of digital technology are easily exposed when compared to their familiar analogue counterparts. But growing concern over disinformation on social media platforms, used by a younger demographic has lead to a rise in technical scepticism across all ages. People have been trained to be sceptical of the unaccountable, the anonymous. We see technology embarrassing itself all the time, so we prefer to trust human moderators. I mean, how many times have you been bombarded with advertisements for products that you would never buy?
This mistrust is antagonised by the fact that very few people understand what an algorithm actually is - and why should they? It's not like it's been widely explained. So here we go: an algorithm is a set of rules, and these rules determine the output of whatever data you input. Simple right?
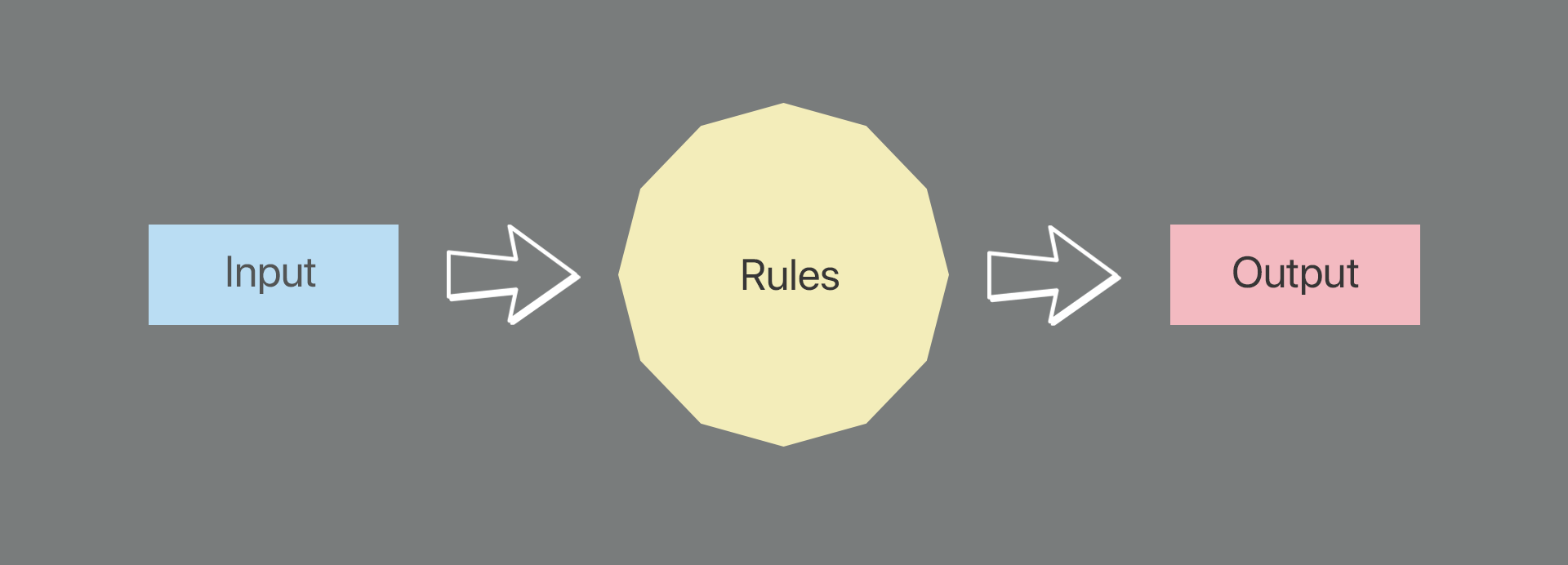
Let's say we have two piles of data: x (CAG grades) and y (past results obtained by the student, as well as their school more broadly). These are fed into the 'algorithm box', which then follows all the rules and spits out something new, z (the adjusted grades awarded to students). Like this:

Just like the mechanisms inside the sausage machine have been designed and constructed by a real person, the rules inside the algorithm box have been written by a human programmer. Crucially, the sausage machine designer started with sausages in mind (I assume). The goal was to produce plump, tender, spirals that maintain structural integrity on the grill; the question was how to get there. Similarly, the rules inside an algorithm box are written based on the desired output.
So for example, Ofqual wanted all the grades to resemble the distribution (how many people receive A,B,C,D,E,U grades) of last year's results, so the algorithm did that. To a certain extent it was a success: the algorithm did what the people created it to do. What failed was Ofqual, the people behind this algorithm, and the fact they decided this was even remotely a good idea. They made three vastly stupid and honestly offensive assumptions:
- Teachers' own assessments can't be trusted
- Grades never fluctuate between years
- An algorithm can account for the complexities of individual groups using only two very limited data sets: teacher-predicted grades, and aggregated past results grouped by school.
These assumptions were built into a piece of software which gave results so off-the-mark they should never have been published. The error, Boris Johnson now claims, was in the 'mutant algorithm' acting of its own accord.
— Matt Singh (@MattSingh_) August 26, 2020
The monstrous whims of machine learning are often used to explain terrible algorithms. It's important to note that the A-level 'algorithm' was not made with machine learning, but we should talk about it for a bit anyway. Machine learning is often described as a 'black box', meaning the intricacy of the machine's operations makes it near-impossible to understand what it's doing to produce its results. This ambiguity can lead to several issues, including the perpetuation and exacerbation of implicit bias (people's subconscious prejudices and stereotypes). We see this a lot with categorising technologies like facial recognition and risk management. The machine is given thousands of images as "training data", but the lack of diversity within those images means - for example - it can't distinguish one Black man from another, so accuses the wrong person of a crime. Because humans chose the input images based on prejudices inside their brains (default photo = white person), you can't trace the fault within the machine itself.
Worryingly this can lead to misplaced confidence in biased decisions, and actually strengthens prejudices - the computer said it so it must be true. People trust the 'complex' workings of technology, rather than looking at the data it was given to work with. I know I said earlier that people distrust tech a lot too, but the world has nuances OK. Anyway, the potential for harm-via-algorithms is a growing concern within the tech community - especially as we become more reliant on machine learning.
But the A-level algorithm is something else. Its design doesn't suffer the issues of 'black box' modelling - the rules are introspectable, written by humans in language we can understand. It is auditable and was designed with intent by humans. The exact reasons behind its decisions can be made available to analyse. Its faults are a direct and traceable result of the humans that made it. In other words, if you buy a new spiral sausage machine ready for the BBQ and it starts spitting out shrivelled, dry cocktail weiners, you go back to the shop or the machine-maker and say this simply won't work for my baps. You don't tell all your hungry guests that the machine must have morphed in the box while on the bus home, or that it's possessed by chaotic spirits like some sort of cruel meat-making Herbie.
Warnings about potential issues with the A level results algorithm were given months in advance by the Education Select Committee. For me, the lack of action over the subsequent weeks suggests a different intent - a determination to produce these results regardless of the ethics behind it. When it's a Tory government approving an algorithm that increases grades at private school by double those at secondary comps and almost three times those at academies, it's not hard to see what the intent might be. As one student put it, "these results feel like a reminder that you shouldn’t dare dream beyond your means". To really flog the metaphor, a cabinet of old Etonians just wanted a machine that would make the empty heads of the grubby peasants into dog meat. And OK if you're being really generous to the old chaps, even if it's unintentional bias rather than explicit intent, they're still culpable.

Instead of calling this shit-show what it is: human-created classism, inequality, and scarcity, the people involved can use 'the algorithm' as a fallback, a perfect scapegoat, a faceless bit of tech that can be blamed with impunity and distanced from wherever possible. It's made to seem like a closed oracle: no one could possibly understand the logic behind its decisions, unlike any normal mark-scheme which is published to the public. 'The algorithm' can be used to produce whatever adjusted grades you want, and you never have to claim ownership of the process, or result. But we must avoid blaming an anthropomorphised 'algorithm' rather than the people that designed it and used it.

The whole thing sets a dangerous precedent. We could soon see 'algorithms' used to implement a wide range of socially abhorrent policies, with their creators exploiting the holes in the general public's understanding of technology to hide their true intentions. Those in power thrive off our unwillingness to discuss our ignorance around advanced technology; we're less likely to probe the information we're given, nor hold its sources to account. Instead, whenever an MP or CEO's decision results in outcry, they assess the damage and quietly u-turn, blaming a misbehaving piece of tech. No resignations needed – it was just a blip.
The A-level disaster was not the first time a controversial decision was blamed on an 'algorithm'. For example, in 2019 Deliveroo briefly introduced a controversial change which seemed to penalise riders for rejecting delivery offers. This algorithm saw the subsequent delivery fee for future deliveries lowered once a rider rejected delivery offers. Deliveroo denied these claims, blaming a technical hitch, but it left many riders angry.
I think it's essential that we remain sceptical whenever a company or government blames a mishap on technology. While its true that technical issues happen frequently (I've had plenty myself), the intention behind such technology must be considered equal to its function. Companies and governments can improve our confidence in their technology by publishing easy-to-comprehend, publicly available documentation of their systems, detailing the technical structure but also the human decisions that lead to its development. I think this is especially important when technology replaces a decision otherwise made by a human, as happened with the A-level results.
Improving public understanding of technology needs to be prioritised as we grow our reliance on automated systems. We're entering an era where there's an algorithm at the heart of most decisions we make in life. Yet the understanding of what that entails is often inaccessible to the majority of people. Because of this, we're leaving ourselves open to deception, coercion and exploitation. And all this only makes governments and corporations quicker and more confident in unleashing the cybergoat 🐐.